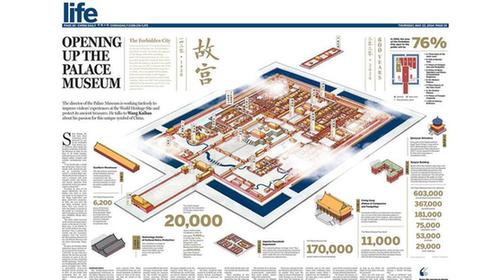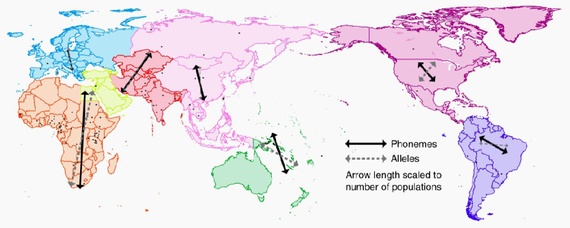
研究数据向我们展示了世界上基因变异与语言变异的发生地点,规模之大可以说是震撼人心的。研究人员在报告中写道:“我们对世界范围内246个种群基于人口统计学历史的微卫星多态性特征与2082种语言的整套音位进行了直观比较。”(微卫星多态性指人人相异的短基因序列。)
这些数据其实原本就已存在,只是从未放在一起比较。报告合作者之一、来自斯坦福大学(Stanford University)的尼可·克林扎(Nicole Creanza)指出:“我们把世界人口的基因特征与其对应的语言相联系,向大家展示对比结果,这是前所未有的。”
利用这套新数据集和新型统计技术,研究人员获得了语言学家和人口统计学家渴求的结果,即语言和基因实际上有着相似的地理断层线。
下图更加详细地为我们展示了研究结果。处于相近地理位置的语言被归纳成树状结构图。灰色圆圈标志着该语言中存在音位/ʈ/(即清音卷舌爆发音)。只有一种语言,即阿萨姆语(Assamese),完全突破了它所在的地理群限制。